
Can Large Language Models Replace Financial Analysts?
A Deep Dive into GPT’s Financial Statement Analysis

A study from the University of Chicago’s Booth School of Business, “Financial Statement Analysis with Large Language Models” by Alex G. Kim, Maximilian Muhn, and Valeri Nikolaev, explores a classic question - Can Large Language Models Replace Financial Analysts? Their findings challenge long-held assumptions about the limits of AI in quantitative reasoning and point to a profound shift in how financial analysis might be done in the future.
1. From Text to Numbers: Pushing LLMs Beyond Their Comfort Zone
Large language models (LLMs) like GPT are best known for processing and generating text. They excel at tasks such as summarizing disclosures, interpreting sentiment, or drafting reports. However, financial statement analysis often called fundamental analysis is traditionally considered a quantitative task. It involves dissecting numbers, interpreting ratios, and applying economic judgment to predict a firm’s performance.
Unlike textual interpretation, this kind of numeric reasoning is not a natural strength for a model trained on language. That’s why this study is so remarkable. The authors strip the experiment down to its purest form: they give GPT only anonymous, standardized balance sheets and income statements, without any narrative or company identifiers. Then they ask it to perform one specific task, predict whether a firm’s earnings will increase or decrease in the next year.
No management commentary. No market news. No fine-tuning. Just numbers. And the results are astonishing.
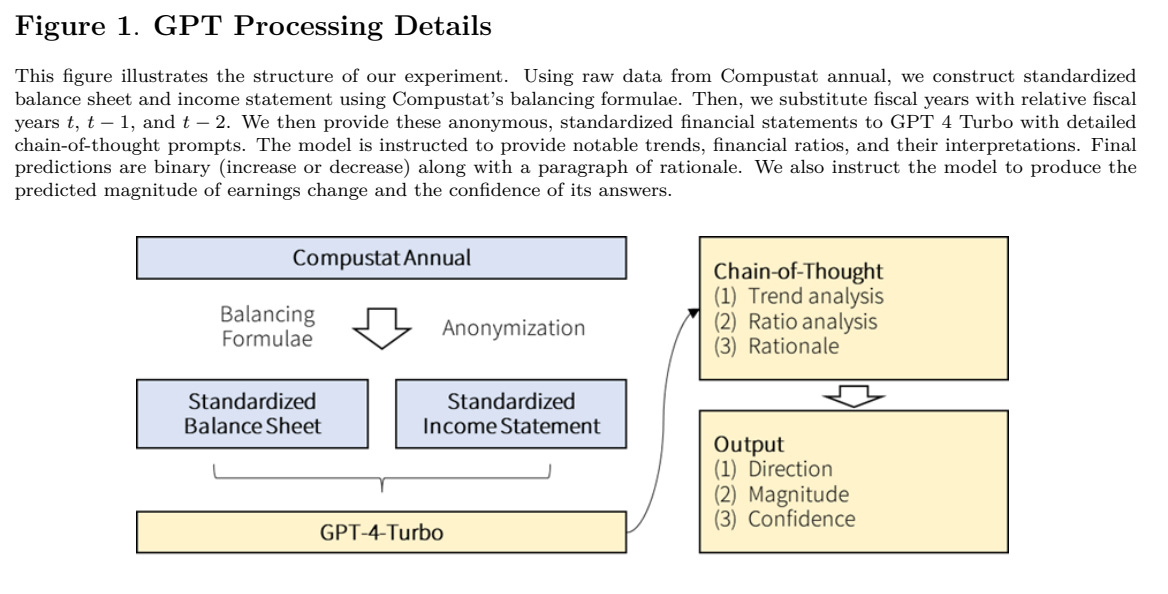
2. GPT Outperforms Human Analysts Even Without Context
The baseline for comparison is clear: human financial analysts, whose forecasts are aggregated in the I/B/E/S database. These analysts, with full access to firms’ financials, management discussion, and market context, correctly predict the direction of future earnings about 53% of the time just slightly above random guessing.
Using a simple prompt, GPT-4 performs similarly. But when researchers introduce a chain-of-thought (CoT) prompt, essentially teaching the model to “think like an analyst” by reasoning step by step, the model’s accuracy jumps to 60%.
That may not sound like much, but in the context of financial forecasting, it’s a stunning result. Predicting earnings changes is notoriously difficult: even sophisticated models and analysts hover just above coin-flip accuracy. In this experiment, GPT-4 not only beats human analysts, but does so using only numbers, without the textual cues analysts typically rely on.
This chain-of-thought prompt appears to be key. It asks the model to:
Identify trends in financial items,
Compute financial ratios such as profitability, liquidity, and leverage,
Interpret these ratios, and
Form a final judgment on future earnings.
By structuring the task this way, the model mimics the reasoning process of a professional analyst in both computation and interpretation.
