FinBen: The Financial Benchmark That Finally Exposes What LLMs Can and Cannot Do
A Benchmark Built to Break the Illusion of Financial Fluency

Finance is where language turns into money, and where small misunderstandings become expensive. Yet most “finance evaluations” for large language models have been narrow, polite, and incomplete. They test whether a model can label sentiment or answer a few questions, then declare victory. FinBen changes that tone. It is a deliberately broad, open-source benchmark built to pressure-test LLMs across the full workflow of real financial work, from extracting entities in SEC filings to answering table-heavy questions, from summarizing market text to making trading decisions under risk.
Why Finance Needed a Benchmark With Teeth
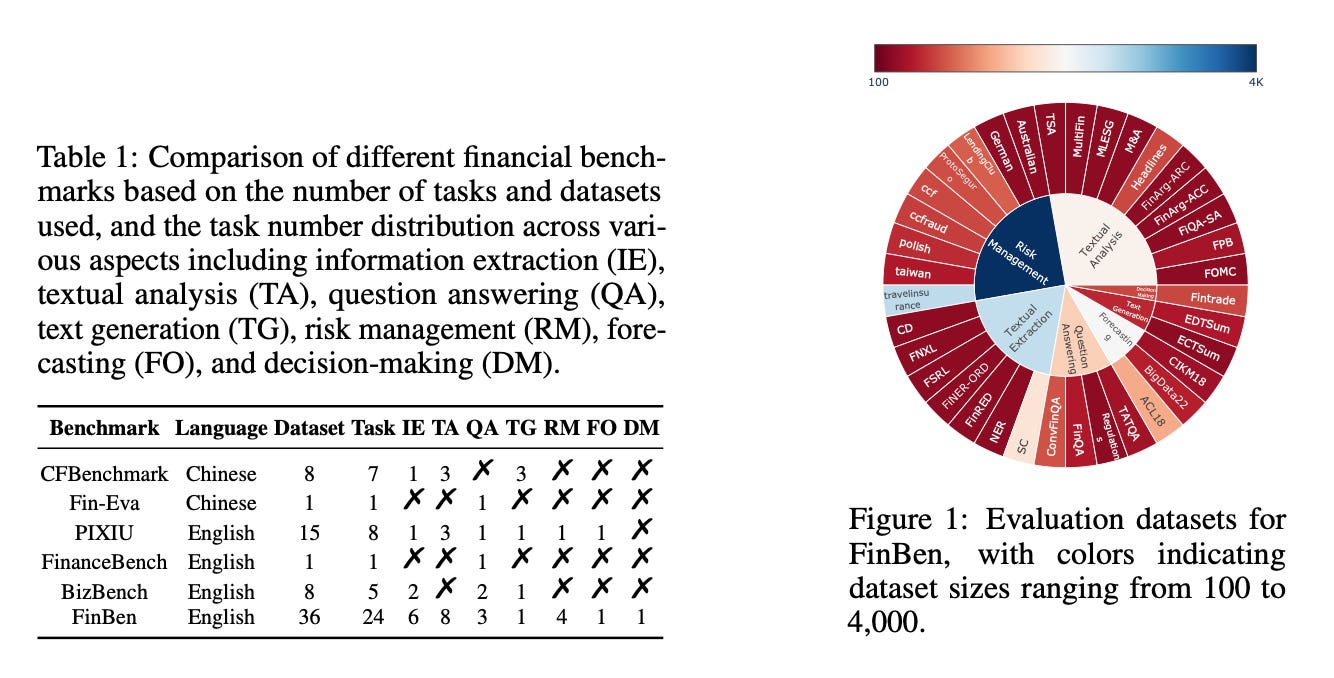
The paper argues that the main bottleneck is not a lack of clever models, but a lack of a comprehensive, standardized exam. Existing benchmarks tend to cluster around a small set of financial NLP tasks. FinBen expands the scope into seven aspects that mirror how finance operates in practice: information extraction, textual analysis, question answering, text generation, risk management, forecasting, and decision-making. Instead of a single dataset per category, it compiles 36 datasets spanning 24 tasks, making it the largest “holistic” evaluation suite of its kind at the time of writing.
The design choice matters. In finance, a model that is strong at sentiment labels but weak at numerical reasoning is not “mostly helpful.” It is a liability dressed as a productivity tool. FinBen is built to reveal that mismatch, and it does so loudly.