
How AI Agents Finally Learn From Their Mistakes
Inside ReasoningBank: The Memory System That Lets Agents Grow Smarter With Every Task

For years, AI agents have promised to navigate websites, fix code, and interact with software the way human assistants do. Yet in practice, they behave more like amnesiac interns. Give an agent a task today, and it will repeat the same mistake tomorrow. The core problem is simple: AI agents do not learn from experience.
Large language models are good at reasoning in a single session, but the moment a task ends, everything disappears. No matter how many times an agent clicks into the wrong menu, gets stuck in loops, or accidentally overwrites the wrong file, it never remembers the lesson. Every task is a reset.
A recent paper from Google introduces a surprisingly elegant solution: ReasoningBank, a memory framework that captures reusable reasoning patterns from both successful and failed interactions, then feeds them back into the agent for future tasks. Combined with a technique called Memory-Aware Test-Time Scaling (MaTTS), the system shows a powerful result: agents begin to self-evolve, getting better over time without additional training, feedback, or labels. If foundation models were the first step, then agents that actually learn in the wild may be the next big leap.
Why today’s agents keep repeating mistakes
Modern LLM agents can browse the web, run software, and generate code, but their abilities are brittle. They often fail for painfully mundane reasons:
They misread the structure of a webpage.
They click the wrong button.
They cannot remember how they solved a similar task before.
They make the exact same mistake across tasks.
Despite being powered by trillion-parameter models, agents behave as if every task were their first. Previous attempts at agent memory fall into two buckets:
1. Raw trajectory storage
Some systems store every past interaction and then retrieve similar histories when a new task arrives. But raw trajectories are long, noisy, and full of irrelevant details. They rarely capture why something worked.
2. Workflow memory from successful tasks only
Other systems abstract successful paths into workflows. These are cleaner, but because they only keep successes, they miss the huge amount of information in failure. They also cannot explain the reasoning behind decisions, only the steps taken.
Both approaches fall short because they do not capture generalizable reasoning. Agents remember actions, but not the principles behind those actions. This is where ReasoningBank changes the game.
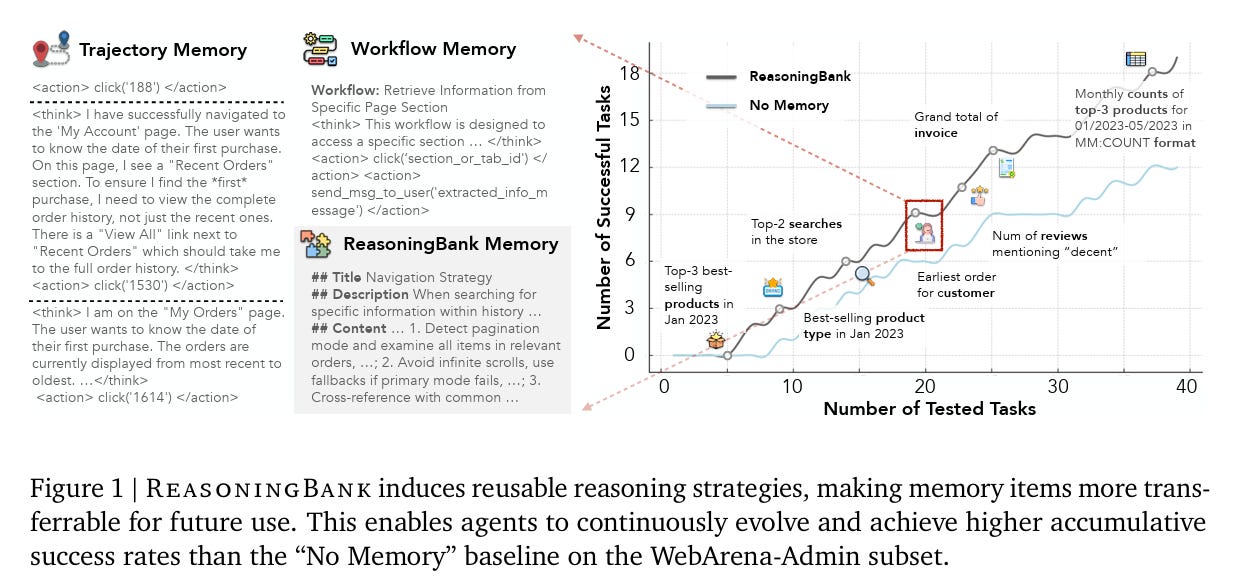
ReasoningBank: A memory system built on strategy, not steps
ReasoningBank introduces a simple but powerful idea: Instead of saving what the agent did, save what the agent learned. Every time an agent completes a task, the system reviews the interaction, labels it as a success or failure using an LLM evaluator, and extracts memory items.
Each memory item includes:
A title (the core idea)
A description (a one sentence summary)
Detailed content (the distilled reasoning or lesson)
A memory item might look like:
Keep reading with a 7-day free trial
Subscribe to LLMQuant Newsletter to keep reading this post and get 7 days of free access to the full post archives.