
LLMQuant Data Has Arrived: The First AI Native Financial Data Ecosystem Built for Agents (Beta)
From chatbot question and answer to professional agent workflows, and the knowledge harness that makes the leap possible.

A Trend That Has Become Impossible to Ignore
Over the past year we have watched a trend grow steadily clearer. Financial AI applications are no longer just ChatGPT style question and answer. They are evolving toward agent workflows that are more professional, more auditable, and far more deployable in the real world. At the start, the way people used large models for financial research was direct and almost charmingly crude. You pasted earnings reports, news, candlestick screenshots, and paper abstracts into a chat window, then asked a single question: help me analyze this. That moment let us feel, for the first time, that financial text and data could be summoned through natural language, that information could be pulled out quickly and arranged into something resembling a research memo.
As the usage deepened, however, the problems grew more obvious. Data was fragmented, with web pages, PDFs, dashboards, spreadsheets, and API documentation each living in their own silo, leaving the agent struggling to integrate any of it. Context was unstable, since the agent could not reliably trace where information came from, which time period or accounting convention applied, or which version it was looking at, and it could not sustain long stretches of work. And professional workflow was missing, because most financial tasks carry specific data requirements and operational steps, and that knowledge is rarely made public anywhere a model can reach.
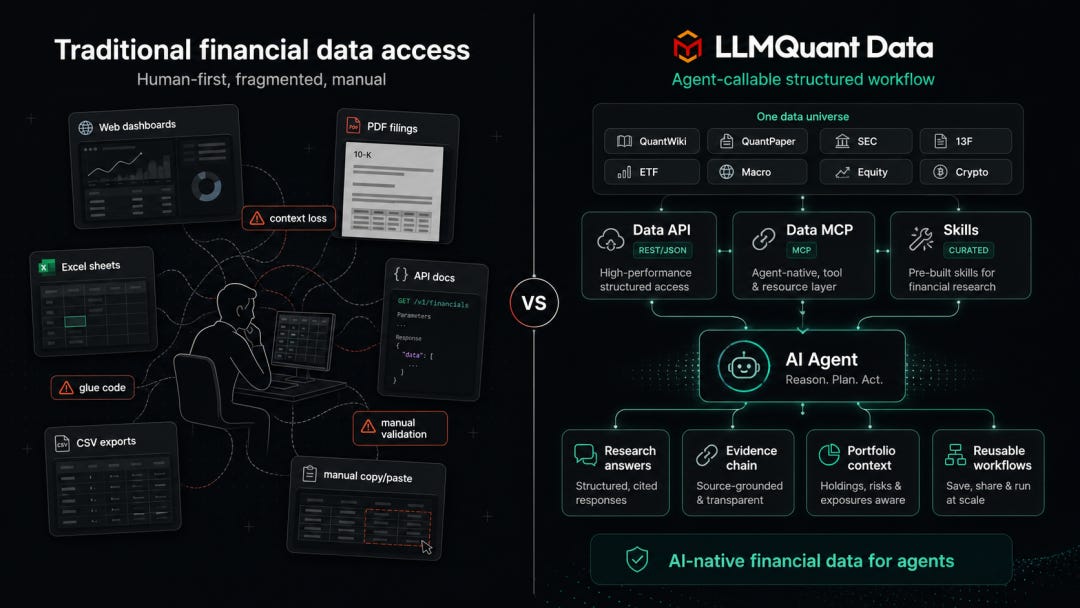
AI finance has moved from chatbot question and answer toward professional agent workflows, and that shift demands a knowledge harness. This is the starting point for building LLMQuant Data and for our effort to create an AI native financial data ecosystem.
A Look at the Product
LLMQuant Data is a financial data platform built for AI agents. We describe it in three lines. It is AI native financial data for agents. It is the knowledge harness for AI native finance. And it is where bespoke workflows meet financial data. LLMQuant Data is neither a traditional financial data website nor merely an API. It is a structured financial data foundation designed specifically for AI agents.
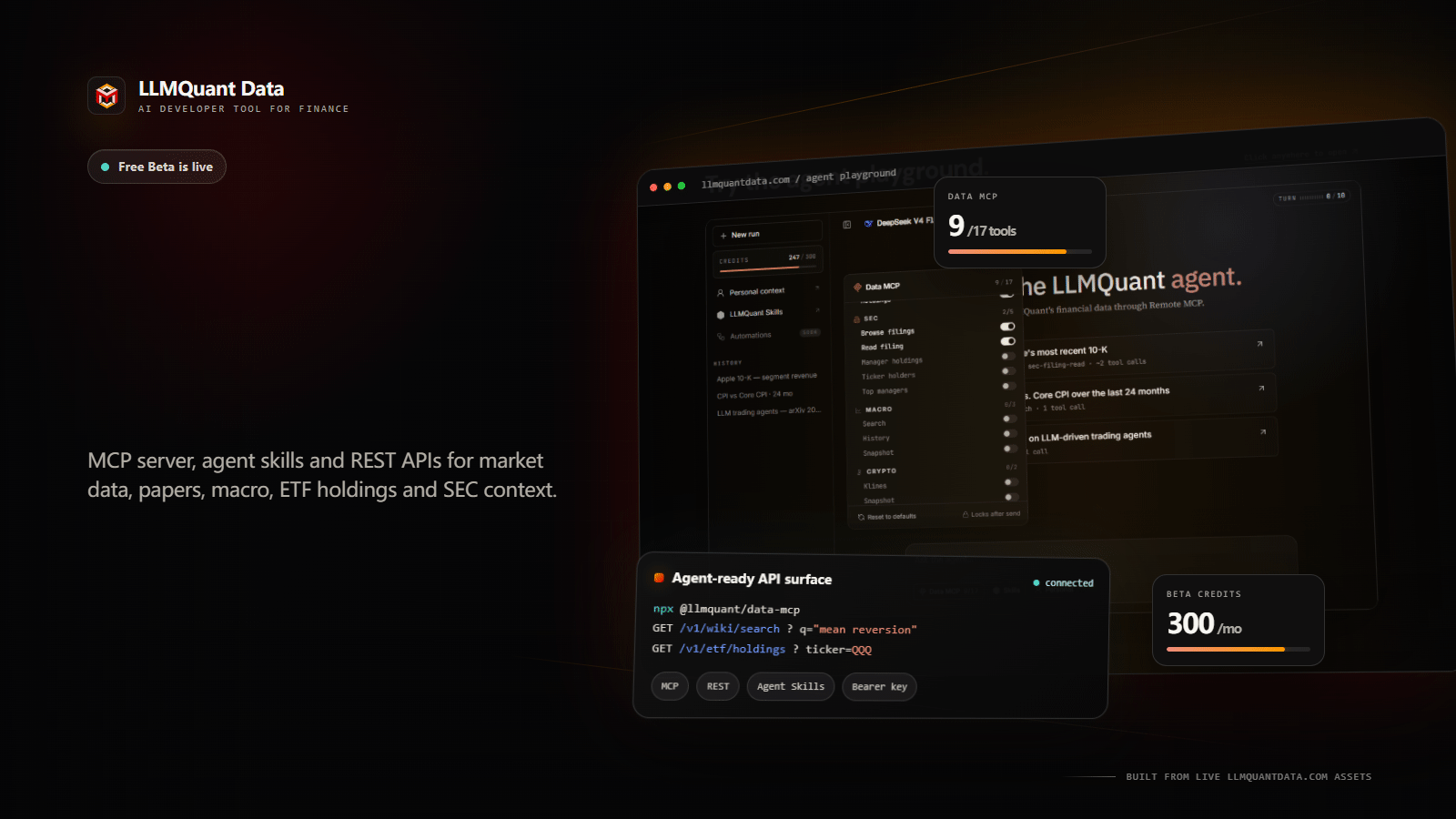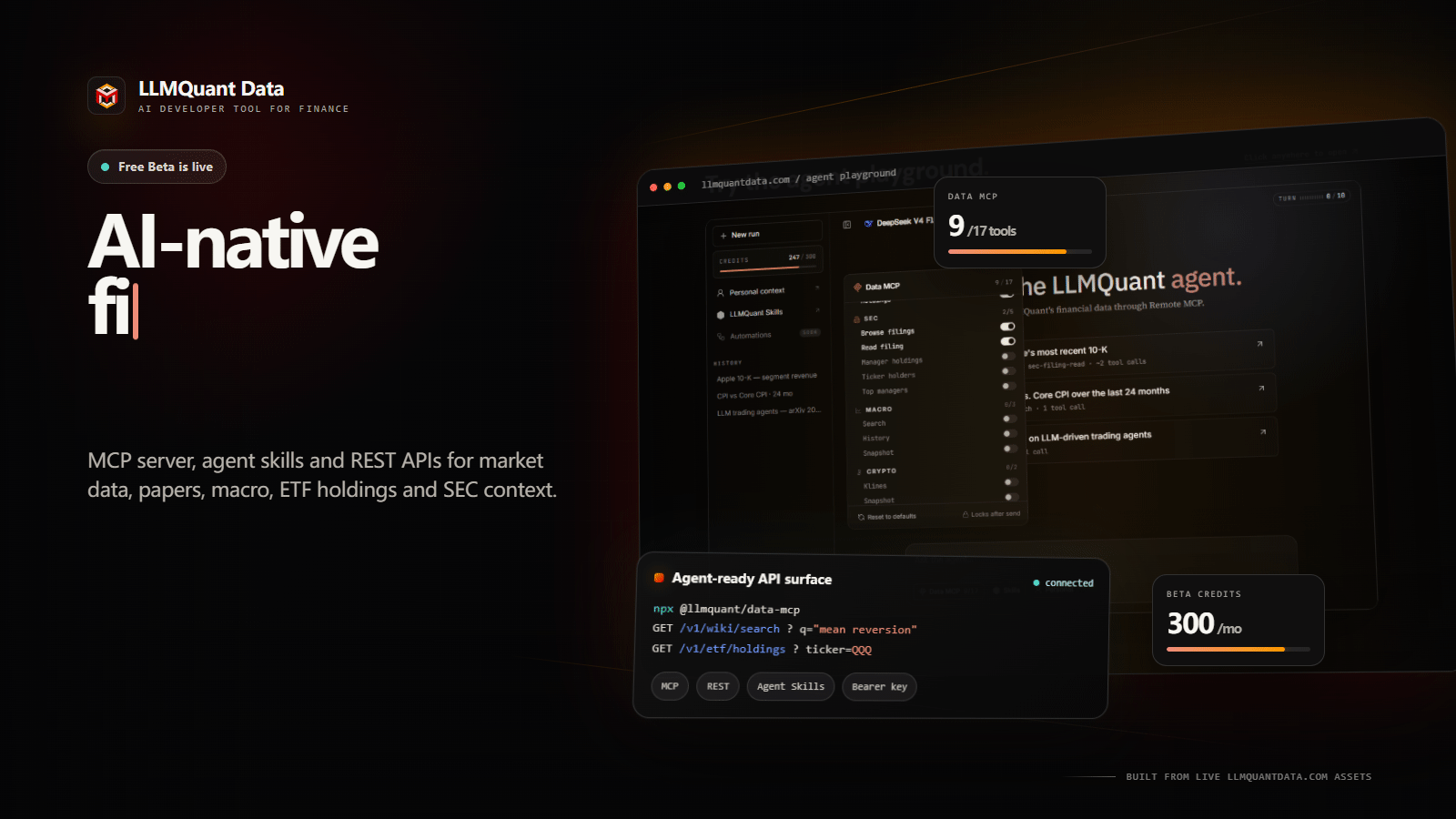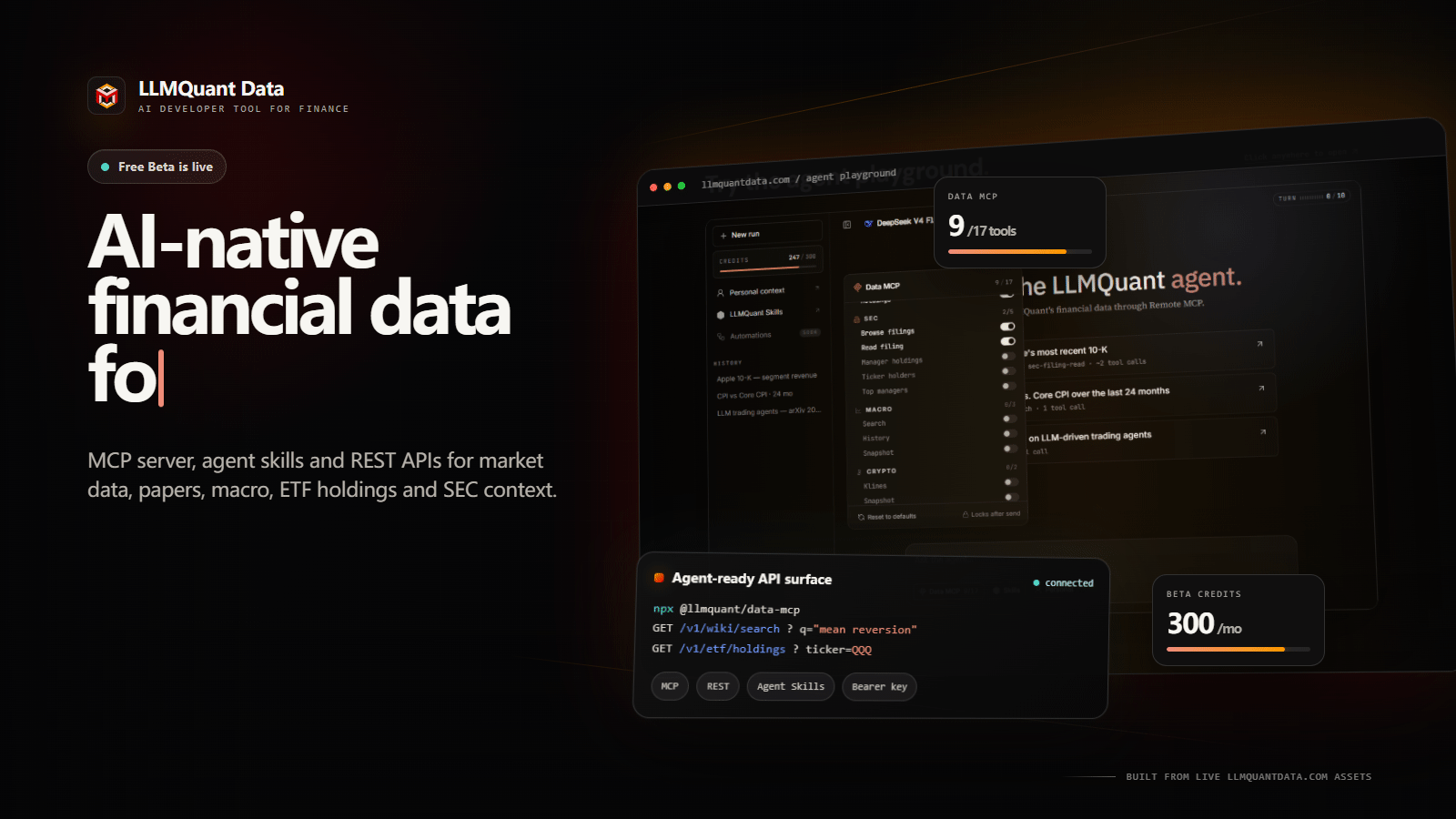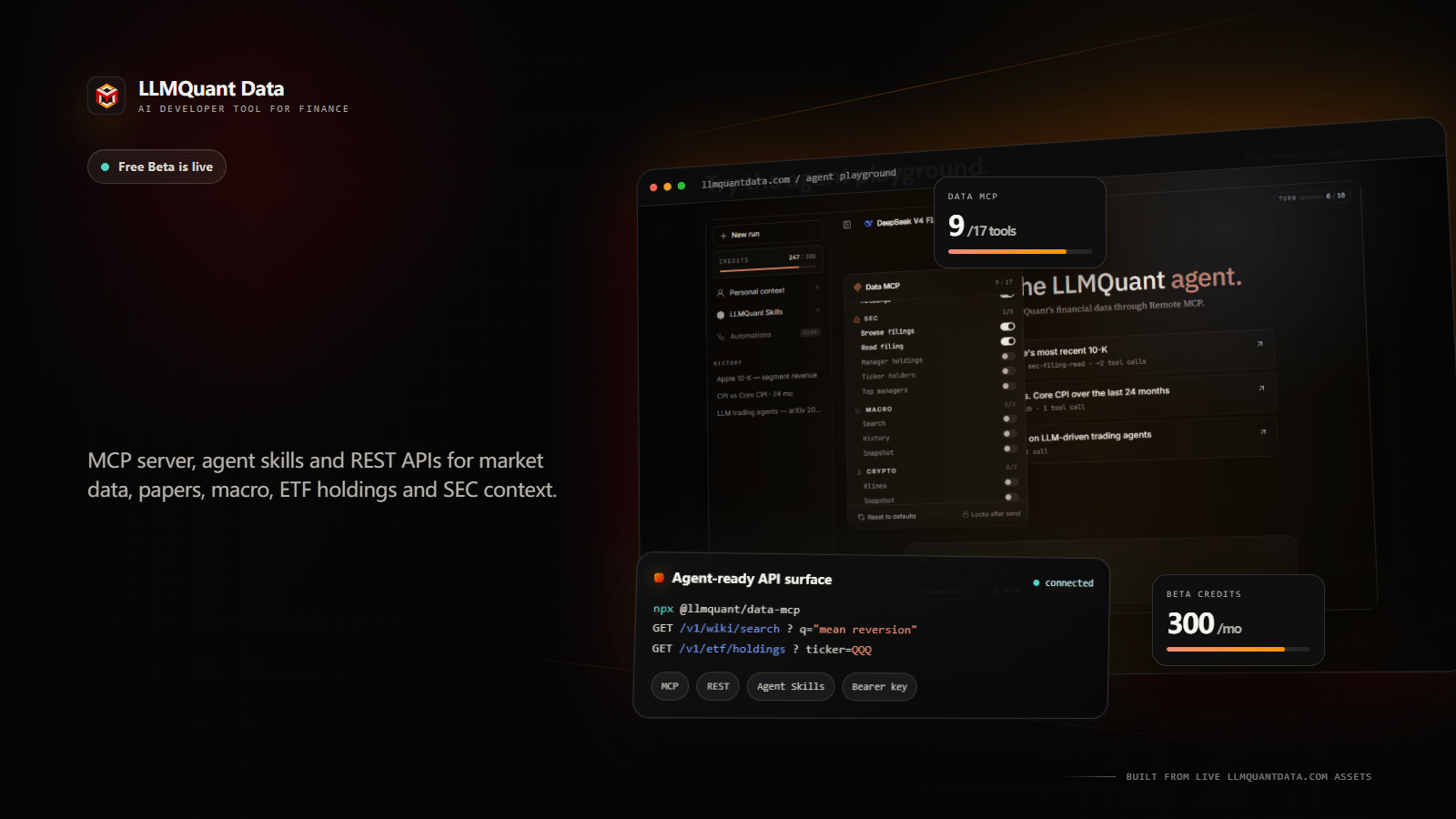
Three Layers of Capability
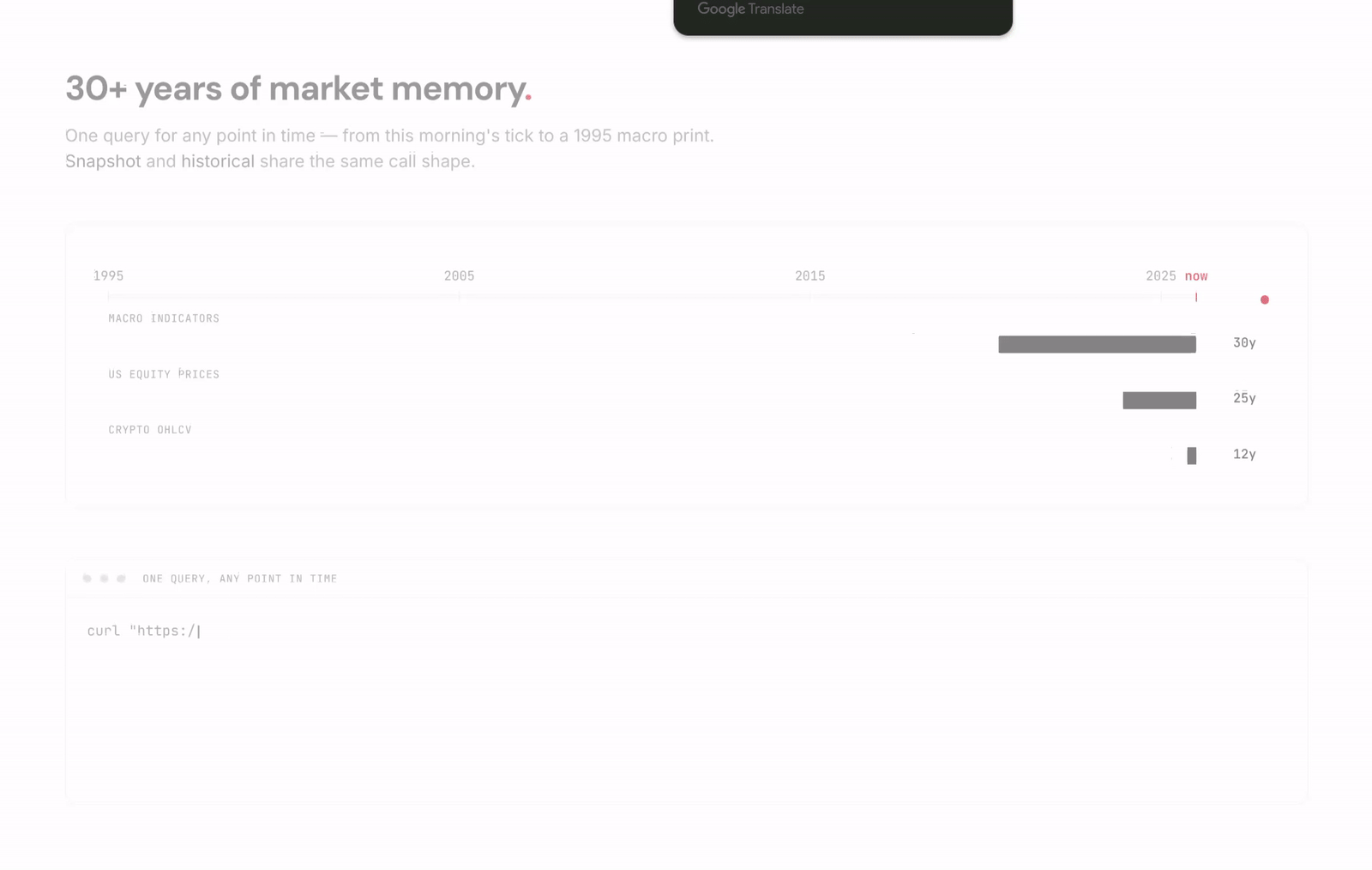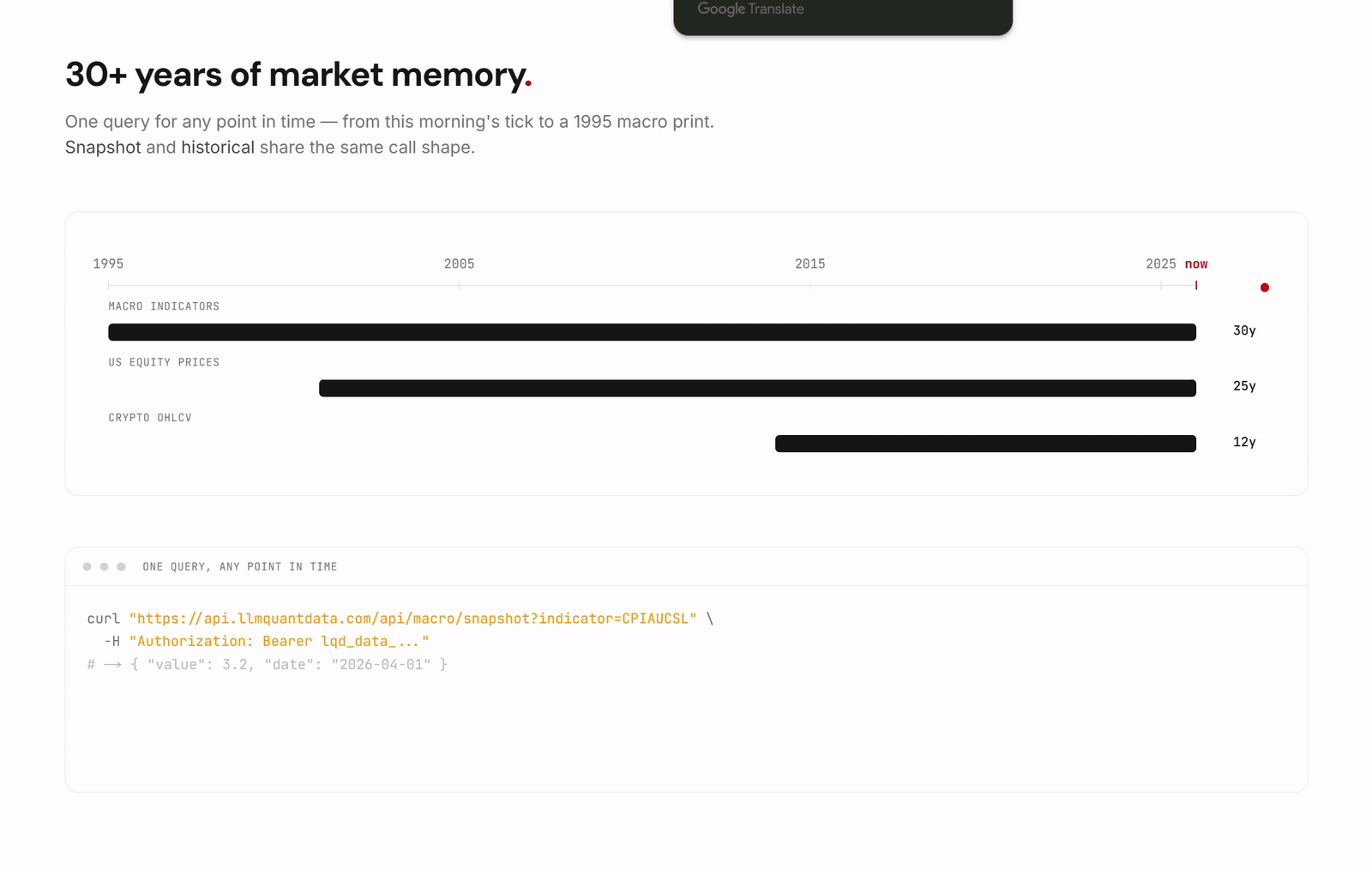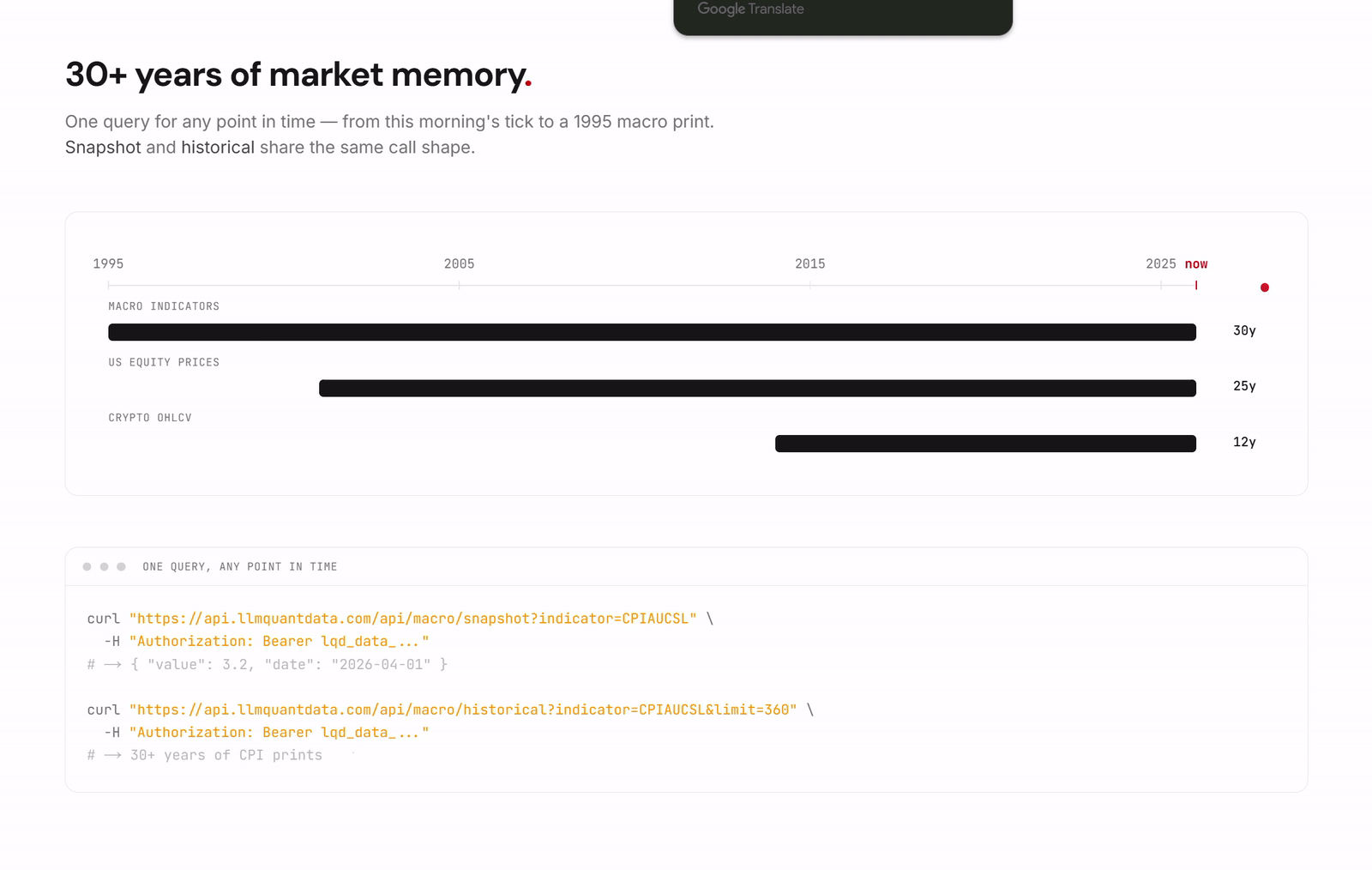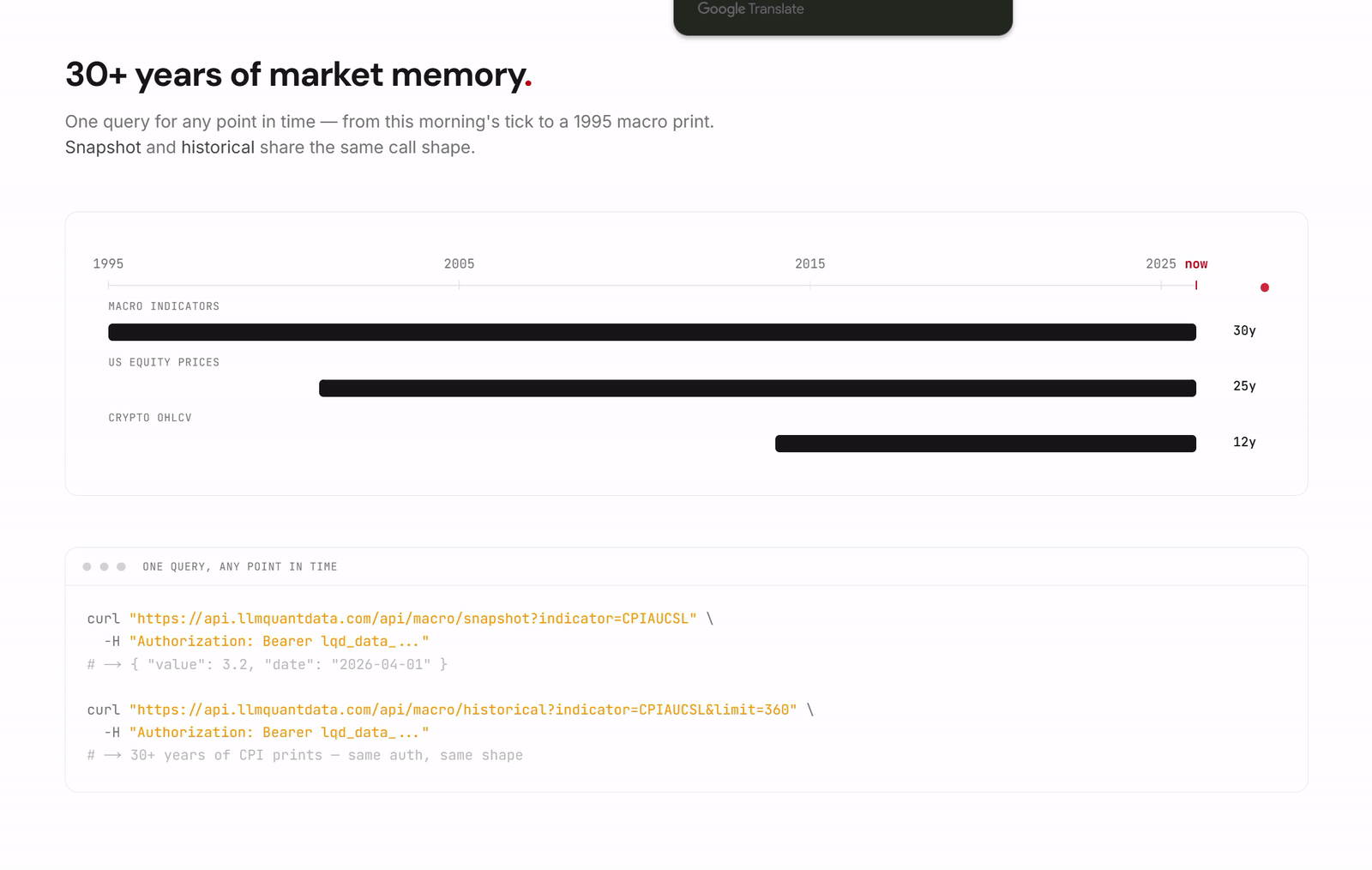
The first layer is financial data and a harness built from the perspective of the AI agent. The Data API is the base layer, providing developers with a unified interface to financial data. During Beta the coverage includes, but is not limited to, QuantWiki, a knowledge base for the frontier of professional financial trading; QuantPaper, which delivers structured retrieval and reading of cutting edge research down to the level of concepts, strategies, and formulas; United States equities, crypto, and macro indicators; and ETF holdings, SEC filings, and insider trading.
The second layer is the Data MCP and its adaptation to mainstream AI tools. MCP is the agent native call layer, and it supports Claude, Codex, Cursor, Gemini CLI, OpenClaw, and others. Through MCP, an agent can invoke the tools of LLMQuant Data directly, with no need for web page parsing or manual intervention.
The third layer is Agent Skills. This is not a simple collection of prompts, nor a single point financial tool. More precisely, it is a library of Agent Skills built for financial investment scenarios, one that settles high frequency research tasks across equities, options, ETFs, macro, credit, crypto, portfolios, and risk into workflows that are reusable, distributable, and auditable. You can find it at github.com/LLMQuant/skills. If LLMQuant Data is responsible for supplying factual input, then LLMQuant Skills is responsible for settling research method. The former answers where the data comes from, while the latter answers how an agent should use that data. Combined, the two let an agent move from knowing how to chat toward knowing how to do research.
A First Taste: Watching an Agent Call Financial Data
We did not want a user opening LLMQuant Data for the first time to see only a string of API documentation, a list of endpoints, and parameter descriptions. Once financial data truly enters the agent era, the point is not merely whether the data exists. The point is whether an agent can break a research question into executable steps, first deciding which data to call, then reading the context, and finally organizing the evidence into a readable result. So in the Beta version we provide the LLMQuant Agent and a Playground for users to experience.
On the LLMQuant Agent page, you can ask questions directly in natural language. Read Apple’s latest 10-K and organize the risks and business changes. Compare the movement of CPI and Core CPI over the past 24 months. Search for papers related to LLM driven trading agents. Query ETF holdings and analyze a given stock’s true exposure inside the portfolio. Behind these questions is not ordinary chat. The agent calls the underlying data tools through remote MCP and completes steps such as search, read, history, snapshot, and filing read.
The Playground is better suited to developers and teams who want to integrate. You can choose an endpoint, enter a ticker, query, or parameters, click Send, and see the JSON response directly. Compared with reading documentation first, it is faster for judging which fields an interface returns, whether the data structure fits your own agent workflow, how the search, read, snapshot, and historical calls should be combined, and whether the returned result can be consumed further by Claude, Codex, Cursor, or an internal agent. Put simply, the Agent lets a user see the effect first, while the Playground lets a developer see the interface clearly. One is responsible for experiencing what an agent can do, and the other for verifying how the data plugs into your own workflow.
The Path to Use: Configure MCP With a Single Line
Connecting quickly into Claude, Codex, Cursor, OpenClaw, or Gemini CLI is straightforward, and the documentation lives at docs.llmquantdata.com/en/introduction. Once you have an API key, you can add the MCP server in the Codex CLI:
codex mcp add llmquant-data \
--env LLMQUANT_API_KEY=your_api_key \
-- npx -y @llmquant/data-mcpClaude Code uses a near identical command:
claude mcp add llmquant-data \
-e LLMQUANT_API_KEY=your_api_key \
-- npx -y @llmquant/data-mcpOnce configured, you can simply ask. Use llmquant-data to query Bridgewater Associates’ latest 13F holdings and produce a one page Smart Money Brief. Or, use llmquant-data to generate a one page macro cross asset radar that checks CPI, the 10 year Treasury yield, and the Fed Funds rate, then compares the recent performance of QQQ, TLT, and BTC. You do not write API call code yourself, and you do not manually clean up the returned format. The agent calls the llmquant-data MCP and then organizes the result into a readable research brief.
The Core Ecosystem: Install Official Skills and Generate Complete Research Workflows
What problem do Skills solve? For many financial agents the difficulty is not that they cannot write, but that they think through the process from scratch every single time. When should they read a 10-K? When should they pull a 13F? Should ETF exposure be judged by true holdings or by the name of the fund? Should macro analysis look at CPI, the 10 year yield, the Fed Funds rate, and cross asset performance all at once? Should portfolio risk check for concentration, hedging, and gaps in the data? The role of Skills is to fix these professional procedures in place, so the agent does not merely answer a question but conducts research by a relatively stable method.
The official Skills currently cover several major financial investment categories, including equity research, ETF analysis, options and derivatives, macro and cross asset, credit, rates, foreign exchange, commodities, crypto, prediction markets, portfolio management, risk management, and the perspectives of investing masters such as Buffett, Graham, Munger, Lynch, and Damodaran. It behaves more like an application pack for financial agents. A user can install a single category on demand, or install the complete repository all at once. To install with a single command:
npx skills add LLMQuant/skillsTo install every category:
npx skills add LLMQuant/skills -g --allOr to install only a few:
npx skills add LLMQuant/skills -g --skill llmquant-equities llmquant-etfs llmquant-macroAfter installation, you can call these workflows directly inside environments such as Claude Code, Codex, Cursor, OpenClaw, and Hermes Agent.
Personalizing the Data: Configuring Personal Context
In financial research the same question should not really yield the same answer for every user. A short term trader, a long term holder, an ETF investor, and an institutional researcher will look at the same stock, the same macro indicator, and the same set of ETF holdings with entirely different points of focus. This is exactly what Personal context inside LLMQuant Data is for. A user can configure long term preferences and working context in their Profile, and once that is done the agent can read this context when it answers, bending the output toward the person doing the asking.
Exclusive Highlights
LLMQuant Data is already adapted for mobile browsing and basic operation. Users can view the product pages on a phone, experience the agent, browse the data capabilities, and inspect key configurations.
There is also QuantMind, the structured knowledge processing engine inside LLMQuant. It is responsible for turning financial text, papers, knowledge entries, and data context into structures suited to agent calls. It supports semantic search, segmented reading, evidence citation, and context stitching, so the agent does not merely find content but reads and uses it step by step according to the research task. Related work is presented at NeurIPS 2025.
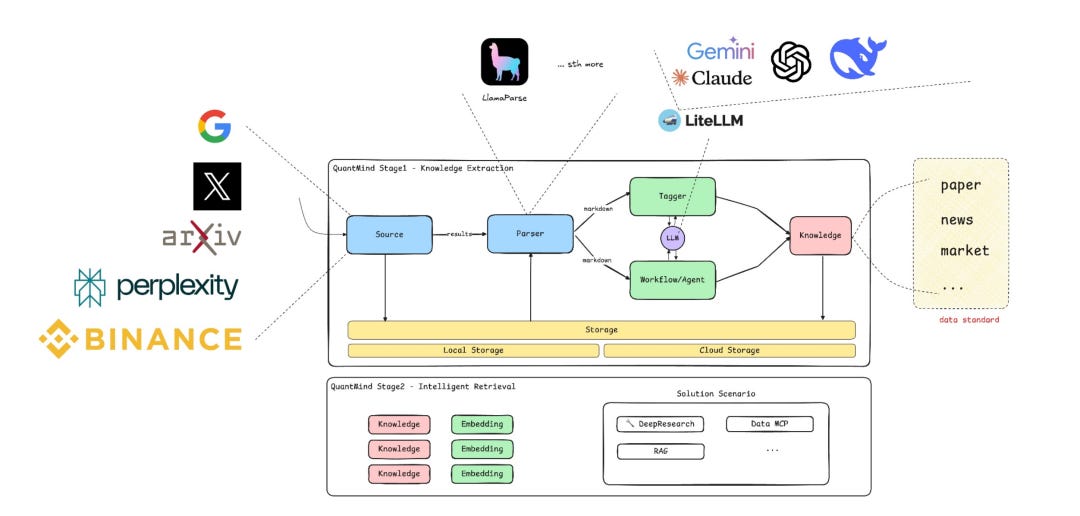
Trial and Plans During Beta
During Beta we offer a Free Plan so that more users can try the product with a low barrier. For users who want higher frequency use, the Beta stage also offers a Plus plan. If you simply want to see what it can do, the Free Plan is already enough to run the complete demo.
Links and Reference
Website: https://llmquantdata.com/
Community: https://llmquant.com/
LLMQuant Agent: https://llmquantdata.com/agent
Data MCP: https://github.com/LLMQuant/data-mcp
LLMQuant GitHub: https://github.com/LLMQuant
Join Discord: https://discord.gg/Ekr4umFBj
The LLMQuant Community Ecosystem
LLMQuant is a research and practice community for the global AI for Trading direction. Around the scenarios of AI financial investment, we are building a complete ecosystem. LLMQuant Data supplies financial data and research context for agents. LLMQuant MCP lets Claude Code, Codex, and other agents call financial data directly. LLMQuant Skills provides reusable AI financial research workflows. Quant Wiki is an open source bilingual quantitative finance knowledge base. Quant Paper offers AI driven paper discovery, semantic search, and knowledge cards. And QuantMind is our self developed engine for financial data and structured knowledge processing. Follow LLMQuant, and observe, build, and validate the next generation of AI trading infrastructure with us.
Join Discord: https://discord.gg/Ekr4umFBj
