
QuantMind: Building an Intelligent Knowledge Framework for Quantitative Finance
By LLMQuant Research - 2509.21507v1

Think about the thousands of pages of SEC filings, earnings call transcripts, broker research reports, and academic papers published every year. For quants, this unstructured information is a goldmine of potential alpha. But turning it into something usable by models and researchers remains a massive challenge.
Recent years have seen a surge in financial language models like FinBERT, BloombergGPT, and FinGPT, as well as the integration of retrieval-augmented generation (RAG) pipelines. These tools represent important progress, but they still suffer from three fundamental limitations:
A lack of point-in-time correctness (models often mix information across dates);
Weak evidence traceability (you can’t see where a generated answer comes from); and
Poor integration with the research workflows used in finance.
QuantMind is an intelligent, context-engineered knowledge framework created by the team at LLMQuant Research. It is designed to extract, structure, and retrieve financial knowledge in a way that’s both machine-readable and research-auditable. In other words, it bridges the gap between large language models and the needs of real-world quant analysts.
Why QuantMind?
Financial research today operates on the intersection of heterogeneous data. The problem is not the lack of models, but the lack of structure. Traditional LLM pipelines treat documents as a collection of unrelated text chunks. This approach works for generic tasks like summarization or question answering but collapses when faced with interconnected, time-sensitive financial data.
QuantMind proposes a two-stage architecture that decouples knowledge extraction from intelligent retrieval. This separation allows the system to guarantee provenance and reproducibility which are two pillars of trustworthy quantitative research.
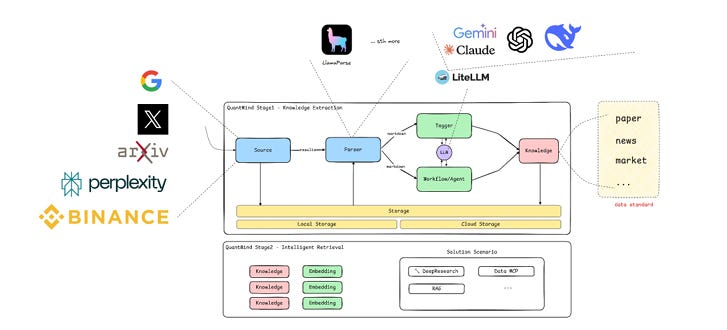
Stage 1: Knowledge Extraction
The first stage of QuantMind is about transforming messy, multi-modal financial documents into structured, searchable knowledge units. The process involves three key components: multi-modal parsing, adaptive summarization, and domain-specialized tagging.
Keep reading with a 7-day free trial
Subscribe to LLMQuant Newsletter to keep reading this post and get 7 days of free access to the full post archives.