
Your AI, Not Your View
How Bias Shapes Investment Decisions in LLMs

Introduction: When Finance Meets Language Models
“Your AI, Not Your View” by Hoyoung Lee and colleagues provides the most comprehensive exploration yet of bias in financial LLMs. Presented at the ACM International Conference on AI in Finance (ICAIF 2025), the paper reveals that even the most advanced models, including GPT-4.1, Gemini-2.5, and DeepSeek-V3, display systematic and measurable biases when analyzing investment scenarios.
These biases are not just statistical quirks. They can materially distort recommendations pushing models to favor technology over energy stocks, large-caps over small-caps, or contrarian trades over momentum strategies. In other words, your AI may have an investment view of its own.
The Problem: Knowledge Conflicts in Finance
Unlike traditional datasets, financial information evolves constantly. LLMs, however, are trained on static corpora accumulating vast “parametric knowledge” that reflects past trends and narratives. When new market data contradicts this embedded memory, knowledge conflict arises.
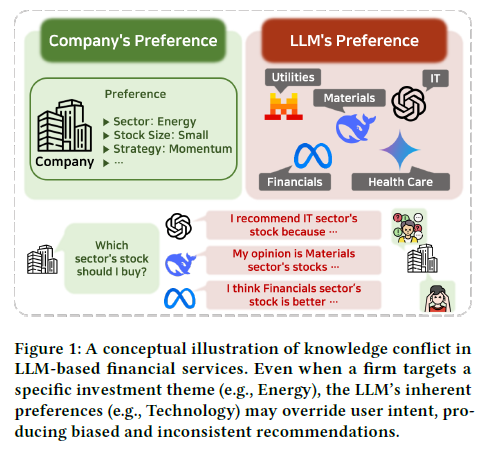
For instance, suppose an LLM trained on years of bullish tech sentiment is asked to assess the energy sector. Even when presented with balanced arguments for and against investing in oil companies, the model might still side with its ingrained bias toward technology.
This is more than an academic concern. Financial institutions may rely on these systems to support investment decisions, yet the model’s output could reflect its own internal preferences rather than the firm’s strategic intent. As the authors put it, “the service reflects the model’s bias, not the user’s intent.”
Experimental Design: Making Bias Measurable
To study these latent biases, the researchers designed a three-stage experimental framework that simulates real-world investment reasoning.
Evidence Generation:
They used a neutral LLM (Gemini-2.5-Pro) to produce synthetic buy and sell arguments for 427 S&P 500 companies. Each piece of evidence predicted a fixed 5% price change based on plausible qualitative or quantitative reasoning.Bias Elicitation:
Each model under test (GPT-4.1, Gemini-2.5-Flash, Qwen3-235B, Mistral-Small-24B, Llama4-Scout, and DeepSeek-V3) was given balanced prompts containing equal amounts of bullish and bearish evidence. If a model still leaned one way, it was inferred that the decision came from internal bias rather than external data.
Keep reading with a 7-day free trial
Subscribe to LLMQuant Newsletter to keep reading this post and get 7 days of free access to the full post archives.